
Welcome to SIM's Data Analytics Club
A supportive community where students share knowledge, build projects, and prepare for a future in tech.

Join Our Workshops
Enhance your skills with our hands-on coding workshops and peer-to-peer mentorship lessons.

Collaborate and Innovate
Work on exciting projects and collaborate with fellow enthusiasts to create impactful solutions.
About Us
We are a student-led club at the Singapore Institute of Management (SIM), established in 2014. Our club caters to students who are passionate about data analytics and data science. We aim to provide a platform for both beginner and advanced learners to explore, learn, and excel in these fields. We do so by focusing on teaching data analytics and data science concepts.
Learn More





DACademy Curriculum Highlights - EDA + Tableau
This session focuses on integrating Exploratory Data Analysis (EDA) techniques with Tableau software to create advanced data visualizations. Participants will learn how to analyze datasets to uncover patterns and insights using Python, followed by leveraging Tableau's visualization capabilities to present findings effectively.
The tutorial emphasizes the synergy between Python's analytical power and Tableau's user-friendly visualization tools, enabling participants to craft compelling data narratives.
Intro To Machine Learning

This introductory course offers a comprehensive overview of machine learning principles and techniques. Spanning multiple lectures, it covers both theoretical foundations and practical applications, guiding participants from basic concepts to more advanced machine learning methodologies.
The curriculum is designed to equip learners with the skills necessary to implement machine learning models, understand their underlying algorithms, and apply them to real-world data scenarios.
Web Scraping

This crash course delves into web scraping techniques using Python. Participants will learn how to extract data from websites efficiently, understanding the legal and ethical considerations involved.
The session covers various tools and libraries essential for web scraping, enabling learners to gather and process web data for analysis and application in data-driven projects.
Intro to NLP

This course provides an introduction to Natural Language Processing (NLP), exploring how machines can understand and interpret human language. Through a series of lectures, participants will learn about fundamental NLP techniques, including text preprocessing, sentiment analysis, and language modeling.
The curriculum aims to equip learners with the skills to apply NLP methods to various textual data, enhancing their ability to develop applications that interact seamlessly with human language.
DSAcademy Curriculum Highlights - Intro To Generative AI

This module provides an in-depth understanding of Generative Artificial Intelligence (AI), focusing on the theoretical foundations and practical coding applications of generative models. It covers various generative models, their architectures, and training methodologies.
The curriculum emphasizes hands-on experience, enabling learners to implement generative models to create new data instances similar to a given dataset. Key topics include Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and their applications in data augmentation, image synthesis, and more.
Emotion Recognition Using Neural Networks
This module covers training a Convolutional Neural Network (CNN) to recognize emotions from human facial expressions. The CNN is trained on labeled face datasets, using preprocessing steps such as resizing, normalization, and grayscale conversion for optimal performance.
After training, the model is integrated into a real-time application that uses a webcam to capture live images, detect faces, and predict emotions. Key challenges like varying lighting, occlusions, and facial angles are addressed through techniques like data augmentation and fine-tuning. By the end, learners will have developed a fully functional emotion recognition system combining machine learning and computer vision.
Reinforcement Learning: Training an RL Agent to Play Flappy Bird
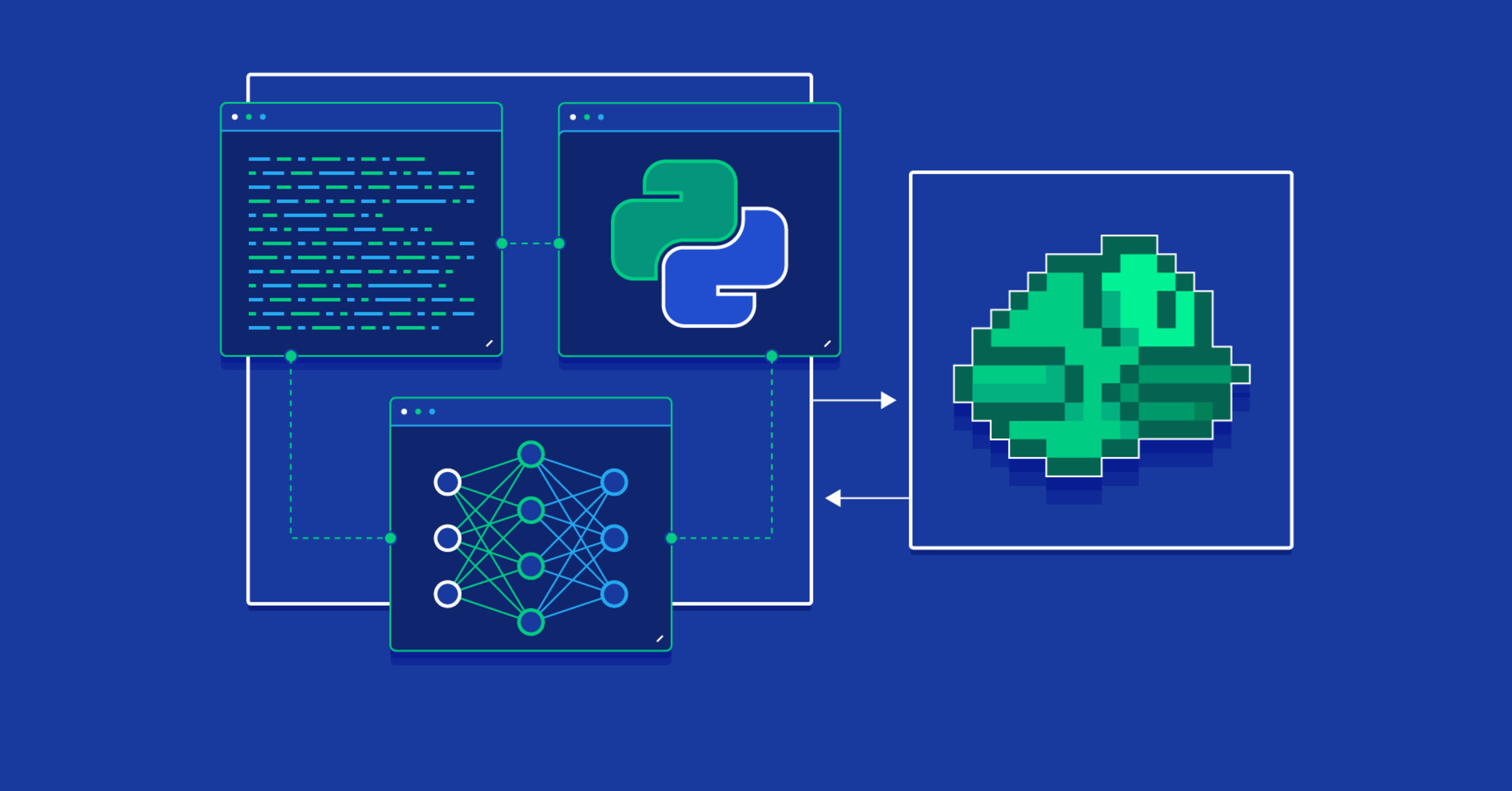
In this practical session, learners are introduced to Reinforcement Learning (RL) concepts by training an RL agent to play the game Flappy Bird. The lesson covers the fundamentals of RL, including the agent-environment interaction, reward systems, and policy optimization.
Participants will implement algorithms such as Q-learning or Deep Q-Networks (DQNs) to enable the agent to learn optimal actions through trial and error, enhancing its performance in the game over time.
Data Engineering Pipeline: Analyzing and Predicting Brain Tumors
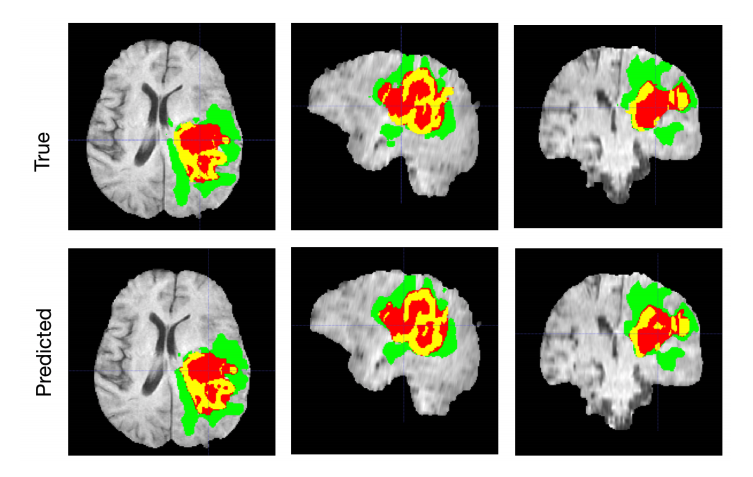
This comprehensive module guides learners through building a data engineering pipeline that integrates SQL, deep learning, and generative AI techniques to analyze and predict brain tumors from a dataset. The pipeline involves data ingestion, cleaning, and transformation using SQL for efficient querying and management.
Subsequently, deep learning models are employed for predictive analysis, identifying patterns indicative of brain tumors. Generative AI is utilized for data augmentation, enhancing model robustness. The lesson emphasizes the end-to-end workflow, from raw data to actionable insights, highlighting best practices in data engineering and machine learning integration.








Contact Us
If you have any questions or want to get in touch, please fill out the form below: